


There’s a divide between continuous integration and day-to-day development. This leads to complicated workflows and duplicate logic that’s hidden away in bash scripts and configuration files.
The Great Divide
Compared to local development, CI is an entirely different context in which to build and test application code. From a developer’s perspective, CI is a parallel universe.
Case in point: My tests fail in CI. You know what? That’s fine. They’re _my _tests, doing what they’re supposed to. The context of what I was working on is still fresh in my mind and tracking down the issue is straightforward.
I’m not as confident when I have to debug the CI config itself. A different operating system with different tools, commands need special flags, and I find myself using YAML as a scripting language. It’s different territory.
Eventually I push my changes. But when the CI server starts up, some minutes later, I realise that I forgot to install <span class="p-color-bg">dep</span>. A few more minutes, but no dice: I forgot Python (of course <span class="p-color-bg">node-gyp</span> needs it). And so it goes.
Simply put, there’s a disconnect between how I run my code when I develop it and how I run my code in CI.
The problem compounds when dealing with complex stacks composed of multiple services:
- Understanding the entire system becomes difficult.
- Integration testing requires dealing with service dependencies.
- For each new service there’s an extra chunk of configuration.
Even with automated workflows for building and testing our code, porting them from local development to CI is difficult.
It’s the imperative nature of how we build and test code that impedes portability. As we develop locally, we give our computer instructions: build this, build that, then test. We then duplicate those instructions in CI, often with a little twist: build this, build that but with a special flag, then test.
We end up with a whole host of bash scripts, imperative configuration, and special cases that we need to maintain for multiple contexts.
However, the primitives are the same: We’re still building and testing chunks of code. Except that how we do it is scattered across scripts and config files and duplicated between contexts.
What we need is structure—and a tool that can tie it all together.
From Source to Finish
With Garden you get structure by declaratively describing each individual component of your application.
How is this one component built? Run? Tested?
The descriptions are co-located with each component, resulting in smaller units of configuration. After all, distributed systems shouldn’t have monolithic configs.
This way we’re able to focus on a single part of the system at a time, and have the tooling do the heavy lifting.
And that is exactly what Garden does.
Garden pulls together the individual components — each relatively simple — and creates a stack graph of your entire system. The stack graph is an opinionated graph structure that holds all the information on how to build, deploy, and test your application, and in what order.
With it, building, testing, and deploying aren’t series of imperative steps anymore — they’re single commands that we can apply in any context. My machine, your machine, and CI server.
As a result, the mental model changes. You’re no longer jumping between disconnected contexts. Instead you use the same tool and the same commands for the entire development cycle.
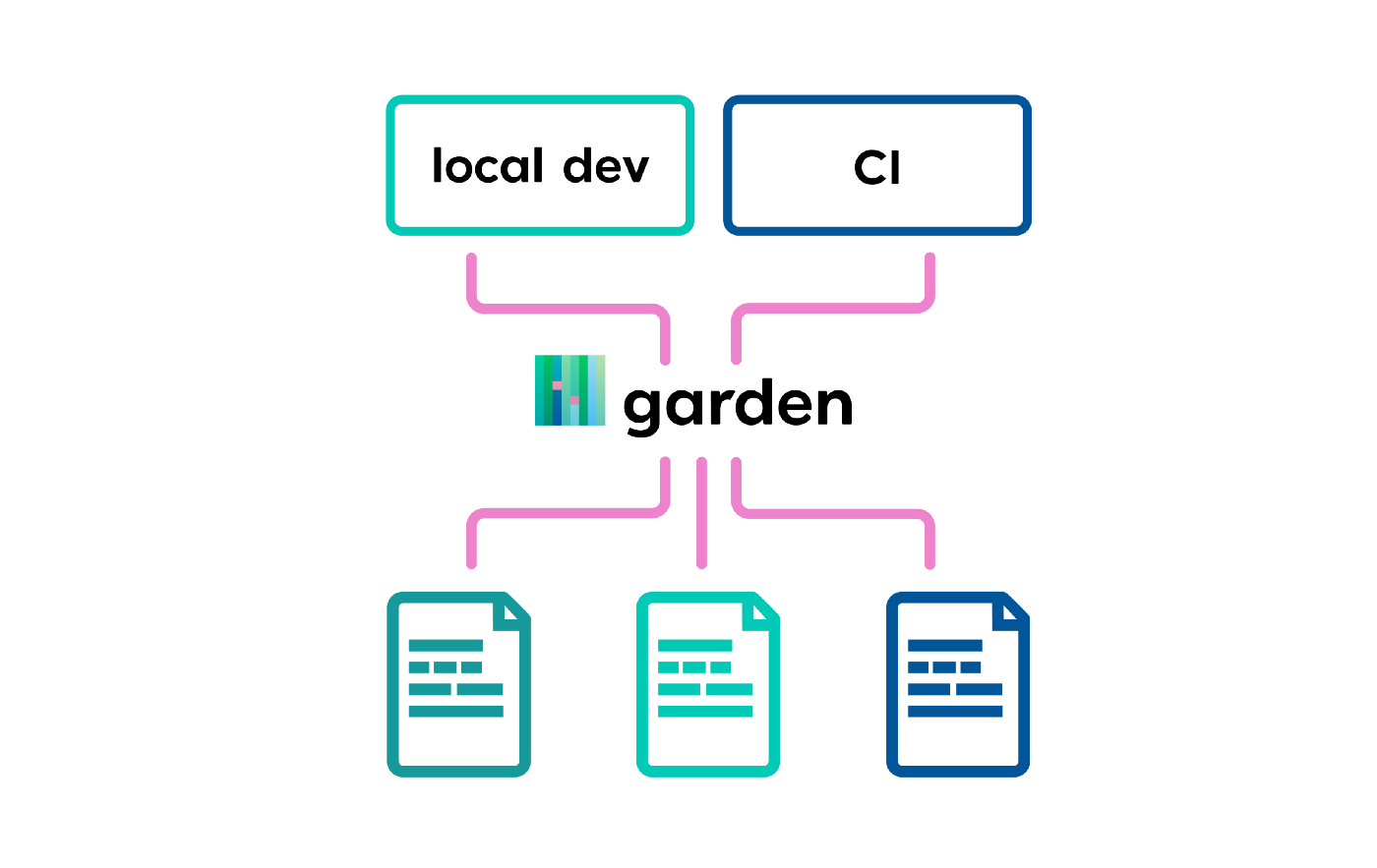
Garden compiles your stack and applies it to different contexts.
For CI, this means:
- Less maintenance. Pipeline configurations don’t change, even as the stack grows and evolves.
- Less configuration. A CI job for a multi-service system is reduced to a single command.
- Less context switching. You use the same tool and the same set of commands in CI and when developing locally.
Let’s see this in action!
CI with Garden
I’ll demonstrate how to set up a project that Garden can build, test and deploy both locally and in CI. The end result is an application that has two services, unit and integration tests, and a fully functioning CI pipeline. The source code is available on Github.
Here’s the plan:
- Configure the first service to work with Garden.
- Set up a CI pipeline that builds and tests the application, and deploys it to a preview environment.
- Add a second service and an integration test.
- Ask ourselves what we need for all this to run in CI. (Spoiler alert: Nothing!)
- Look at some more cool stuff Garden can do in CI.
For a more detailed, step-by-step guide, please check out the Garden documentation.
Project Overview
The project consists of two services, aptly named <span class="p-color-bg">frontend</span> and <span class="p-color-bg">backend</span>, and written in Node.js and Golang respectively. The <span class="p-color-bg">frontend</span> depends on the <span class="p-color-bg">backend</span>, and so do the <span class="p-color-bg">frontend</span> integration tests. Both services are containerised.
We’re using CircleCI as our CI platform for this demo. Pushing a commit to Github triggers a CircleCI job that builds and tests the entire project and then deploys it to a preview environment.
Configuring the Project
The first service is a simple web server written in Golang. All it does is return “Hello from backend!” when you call it.
To use it with Garden, we place a <span class="p-color-bg">garden.yml</span> config file into the same directory. The file looks like this:
We also need a project-level config file that specifies what environments we want to use:
We start with a <span class="p-color-bg">local</span> environment and deploy the project to a local Kubernetes cluster (Docker for Desktop or Minikube) using the <span class="p-color-bg">local-kubernetes</span> provider.
This is all Garden needs to build, deploy and test the backend module.
If we now run <span class="p-color-bg">garden test</span>, Garden will build the module and run the unit test we specified in the backend <span class="p-color-bg">garden.yml</span> file. The test runs in an instance of the container image in our local Kubernetes cluster.
Adding a Remote Environment
Next, we’ll add a remote preview environment:
The preview environment uses the <span class="p-color-bg">kubernetes</span> provider and includes some information about our cluster that the provider needs. Here’s the full configuration.
To test the application in the remote environment, we simply run <span class="p-color-bg">garden test --env preview</span>. And we deploy it with <span class="p-color-bg">garden deploy --env preview</span>.
During development it’s convenient to use the <span class="p-color-bg">garden dev</span> command. It builds, tests, and deploys the entire project and watches the codebase for changes. Thanks to the stack graph, Garden only rebuilds and re-tests what’s needed when it detects a change.
CI Config
Now we just need the CircleCI configuration. You’ll find the entire config file here. Below I’m only showing the <span class="p-color-bg">jobs</span> part. As promised, it’s short and sweet:
Let’s break it down:
- We tell CircleCI to use the official Garden Docker image.
- We configure the Kubectl context. This step will depend on how you’ve set up your remote cluster and is explained in more detail in the step-by-step guide.
- And then we test and deploy the project with Garden. (Our default logger does a lot of fancy things that don’t play well in CI, that’s why we’ve set the logger type to basic.)
Adding a Frontend
Let’s see what happens after we add a frontend service and an integration test. Here’s a link to the full configuration. The important bits are below:
The <span class="p-color-bg">frontend</span> service and the integration test depend on the <span class="p-color-bg">backend</span> service being up and running. The test calls the backend and checks whether it gets the correct response. Here’s the test file.
We can now run the entire test suite for both services with <span class="p-color-bg">garden test</span>, just like before. Garden will build and deploy the <span class="p-color-bg">backend</span> if needed, before running the integration test.
Now lets turn to our CI config to add the new service and the tests. No wait! We don’t have to.
The CI config is the same, even though we’ve added a new service — written in a different language and with its own set of dependencies — along with the integration test.
This is because Garden holds the entire stack graph. It knows how and when to build, test and deploy our system. We only focus on describing each individual component. And as our application grows and evolves, our workflows remain the same.
To summarise, we:
- Created a Garden project and configured both a local and a preview environment.
- Set up a CI job that uses the Garden Docker image.
- Added a <span class="p-color-bg">garden.yml</span> configuration file to each new service.
Going forward
This example barely scratches the surface and there are many more features to uncover. In a real world project we might want to:
- Add a staging environment for merges to <span class="p-color-bg">master</span>.
- Dynamically configure services and environments with template strings.
- Publish built Docker images to a remote registry with the <span class="p-color-bg">garden publish</span> command.
Conclusion
Our applications run in a lot of different contexts but the basic primitives of building, testing, and deploying apply throughout.
By describing the components of our system in a structured, codified manner—and having a tool to bring it all together—we can erase the boundary between these contexts.
Check out our project on GitHub. The Garden orchestrator is free and open-source, and we’d love to hear your feedback!